Python Support in Snowflake

The Snowflake cloud-based data storage and analytics service has Python capabilities as part of its offerings. Snowpark offers native Python integration into Snowflake's execution engine. Therefore, Python can be used to extend, call, and trigger data pipelines inside their managed virtual warehouse infrastructure.
The Snowpark Python integration offers three ways to use Python inside Snowflake:
Python user-defined functions (UDFs): A user-defined function in Snowflake is called as part of SQL statements to extend functionality that is not part of the standard SQL interface. To address the performance issues that come with row-wise execution, Snowpark also offers a vectorized mini-batch interface for user-defined functions.
Python stored procedures: Stored procedures in Snowflake are called as an independent statement; you cannot call a stored procedure as part of an expression. A stored procedure can return a value, but this cannot be passed to another operation. It is possible to execute multiple statements within a stored procedure.
Snowpark Python DataFrame API: A DataFrame/PySpark-like API to query Snowflake data and execute data pipelines. Snowflake transparently transforms the DataFrame statements to SQL at execution time and benefits from the SQL query optimizer.
Creating a scalar user-defined function in Python
You can define user-defined Python functions and call them like normal SQL functions in Snowflake. These UDFs are scalar functions: each row is passed into the UDF and a single value is returned. Compared to built-in SQL functions or UDFs in JavaScript, runtime performance is lower because Snowflake has to convert every value to a Python type and do the same on the output side. For performance-critical workloads, Snowflake offers a batch UDF API that works with pandas DataFrames (see below).
Still, Python scalar UDFs are very useful if you want to extend your SQL statements with Python code.
CREATE OR REPLACE FUNCTION sizeof_fmt(val number)
returns text
language python
runtime_version = 3.8
handler = 'fn'
AS
$$
def fn(val):
for unit in ['','Ki','Mi','Gi','Ti','Pi','Ei','Zi']:
if abs(val) < 1024.0:
return "{:3.1f}{}B".format(val, unit)
val /= 1024.0
return "{:.1f}{}B".format(val, 'Yi')
$$
;
The example below calculates a human-readable version for large numbers and uses it within a query to get the database sizes from the information schema:
select
usage_date,
database_name,
average_database_bytes,
sizeof_fmt(average_database_bytes)
from
table(snowflake.information_schema.database_storage_usage_history(
dateadd('days',-10,current_date()),current_date()));
This returns a readable result set:

Create User-Defined Function with the Python UDF Batch API.
The Python UDF Batch API offers a faster way to process batches of rows. It exposes an interface that works directly on pandas DataFrames or NumPy arrays.
The following trivial example uses arithmetic in pandas. In a follow-up blog post, we will use this functionality to do online scoring with a logistic regression from scikit-learn.
create function add_one_to_inputs(x number(10, 0), y number(10, 0))
returns number(10, 0)
language python
runtime_version = 3.8
packages = ('pandas')
handler = 'add_one_to_inputs'
as $$
import pandas
from _snowflake import vectorized
@vectorized(input=pandas.DataFrame, max_batch_size=1000)
def add_one_to_inputs(df):
return df[0] + df[1] + 1
$$;
The pandas user-defined function can then be used as usual within SQL statements
with features as (
select
row_number() over (order by false) as a,
pow(2, row_number() over (order by false)) as b,
uniform(1, 100, random()) as c
from table(generator(rowcount => 10))
)
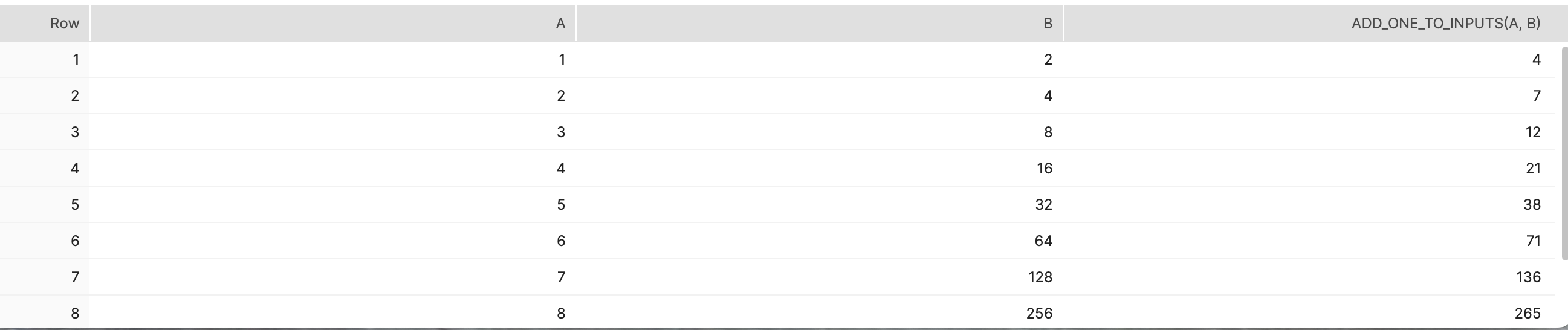
select a, b, add_one_to_inputs(a, b) from features;
Python Stored Procedures
Stored procedures in Snowflake are called as an independent statement; you cannot call a stored procedure as part of an expression. A stored procedure can return a value, but this cannot be passed to another operation.
It is possible to execute multiple statements within a stored procedure. Inside a stored procedure, you have access to the same Session object as with the Python Snowpark API
The Session object is passed implicitly into the execution function.
CREATE OR REPLACE PROCEDURE MYPROC()
RETURNS STRING
LANGUAGE PYTHON
RUNTIME_VERSION = '3.8'
PACKAGES = ('snowflake-snowpark-python')
HANDLER = 'run'
AS
$$
def run(session):
stm = 'CREATE OR REPLACE TABLE sample_product_data (id INT, parent_id INT, category_id INT, name VARCHAR, serial_number VARCHAR, key INT, "3rd" INT)'
res = session.sql(stm).collect()
return str(res)
$$;
It is also possible to execute multiple statements within the stored procedure. This is useful for DB maintenance tasks, etc.
The stored procedure can be called like any other native stored procedure:
call MYPROC();
It will create the sample_product_data table and yield the following output:
