Tenant Isolation in Snowflake for ML - Operational Patterns

Hands-on patterns for operating Snowflake-backed ML platforms at scale. It covers tenant data duplication strategies, environment promotion workflows, ML experimentation with real customer data under strict controls, and operational trade-offs between cost, safety, and velocity.
Building on the conceptual foundations my previous article Tenant Isolation in Snowflake, this follow-up explores the practical and operational realities teams face when running multi-tenant ML workloads in production. While isolation strategies are often discussed at the data-modeling or security level, ML systems introduce additional complexity: tenant-aware data copies for experimentation, safe access to customer data in lower environments, reproducible model testing, and CI/CD-style deployment pipelines spanning dev, staging, and prod.
This post focuses on hands-on patterns for operating Snowflake-backed ML platforms at scale. It covers tenant data duplication strategies, environment promotion workflows, ML experimentation with real customer data under strict controls, and operational trade-offs between cost, safety, and velocity. The goal is to provide concrete guidance for teams who already understand tenant isolation in theory and now need to make it work reliably for ML-driven products.
Recap: Tenant Isolation — From Concept to Operations
Before diving into ML-specific challenges, let’s briefly recap the main tenant isolation strategies in Snowflake, as discussed in the original post:
| Strategy | Isolation Strength | Characteristics | Best For |
|---|---|---|---|
| Separate Snowflake Accounts per Tenant | Strongest | Each tenant has its own Snowflake account, users, warehouses, and data. High operational overhead. | Large/regulated customers requiring maximum security, compliance, and cost attribution |
| Shared Account, Separate Databases per Tenant | Strong | Each tenant gets a dedicated database within a shared account. Easier cost tracking, but some shared blast radius. | Most multi-tenant scenarios balancing isolation with operational efficiency |
| Shared Database, Separate Schemas per Tenant | Moderate | Each tenant has a schema in a shared database. Lower overhead, but weaker boundaries and risk of privilege mistakes. | Medium-scale deployments with trusted tenants |
Shared Tables with tenant_id Column |
Lowest | All tenants share tables, isolation enforced by row access policies and application logic. Highest scale, but weakest isolation and higher risk of data leaks. | Many small tenants where operational simplicity and scale are prioritized |
Machine learning applications fundamentally differ from traditional software because their behavior is shaped jointly by code and continuously evolving data, which necessitates architectures that treat data pipelines, model lifecycle, and feedback loops as first-class, tightly integrated components rather than peripheral concerns. So ML workloads introduce new and more dynamic challenges to the architecture:
Production model monitoring and validation: In production, teams must continuously monitor, validate, and analyze ML model quality for each tenant. This requires access to up-to-date tenant data, robust logging, and the ability to attribute model performance issues to specific tenants or data segments.
ML training lifecycle: The ML lifecycle involves retraining models on fresh tenant data, evaluating new model versions, and promoting them to production. Each stage (training, evaluation, deployment) requires data access to production data, especially when rolling out models incrementally or running A/B tests.
Experimentation in lower environments: ML development is highly iterative—data scientists and engineers need to experiment with new models, features, and preprocessing pipelines in dev/staging environments. This often means working with realistic (sometimes real) tenant data, which increases the risk of data leakage and requires careful controls.
Data quality checks and remediation: Data quality issues are often detected in production, but fixes and validation must be applied in lower environments first. This workflow requires safe, auditable ways to copy, mask, or anonymize tenant data for debugging and remediation without violating isolation boundaries.
Reproducibility: ML pipelines need consistent, isolated snapshots of data and code.
Automation & cost: Frequent cloning, cleanup, and environment promotion can drive up costs and require robust automation.
Compliance: ML experiments may touch sensitive data, raising the bar for auditability and blast-radius reduction.
The rest of this article explores how to adapt and extend the isolation patterns to meet the operational realities of multi-tenant ML platforms.
Environment Topology for Multi-Tenant ML Systems
A typical environment structure maps to the standard dev, staging, and prod environments and applies extra requiements on how you segment tenants to achive safety, velocity, and managable operational complexity:
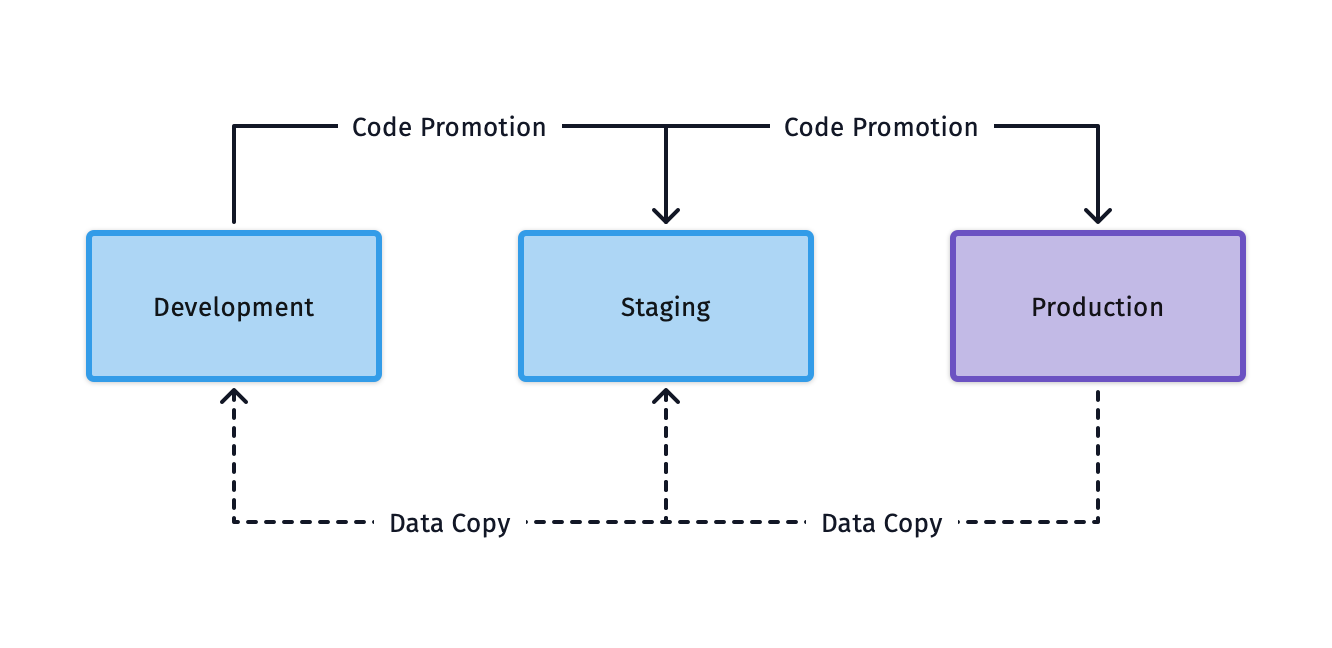
Development: For rapid iteration, experimentation, and debugging. Data scientists and engineers need flexibility. Guardrails are put in place (technically and operationally) that no sensitive/customer data must be used in the development environments to prevent accidental data leaks. All ML development in this environment must only use anonymized or synthetical data.
Staging: A pre-production environment for integration testing, model validation, and data quality checks using production-like data. Staging is where you catch issues before they impact customers. It should be possible to copy data from a production tenant to a staging tenant in a controlled way to validate ML Model behaviour.
Production: The live environment serving real tenant workloads, where safety, auditability, and performance are paramount.
There are two main patterns for mapping environments in Snowflake:
Account-per-Environment: Each environment (dev, staging, prod) gets its own Snowflake account. This provides the strongest isolation—no risk of accidental cross-environment data access, and clear separation of roles, warehouses, and billing. However, it increases operational overhead and complicates automation and cross-environment analytics. Tenenat/Data copies between accounts become more complex and you cannot benefit from Snowflake zero copy cloning capabilities.
Database-per-Environment: All environments live in a single Snowflake account, separated by databases(e.g.,
myapp_dev,myapp_staging,myapp_prod). This reduces cost and simplifies automation, but increases the risk of accidental data access across environments and requires stricter RBAC and naming conventions.
The challenge multiplies when you add tenants. For each environment, you must decide how to isolate tenants:
Account-per-tenant-per-environment: Maximum isolation, but operationally heavy and rarely justified except for the largest, most regulated customers.
Database-per-tenant-per-environment: A common compromise—each tenant gets a database in each environment. This enables per-tenant backup, restore, and lifecycle management, but can lead to database sprawl as the number of tenants grows.
Tenant Data Copy Strategies in Practice
Effective data copy strategies are essential for enabling safe ML experimentation, model retraining, and debugging in multi-tenant Snowflake environments. The design needs to balance complexity, speed, cost, and risk—especially when working with sensitive or large-scale tenant data.
Zero-Copy Cloning for Tenant-Scoped Datasets
Snowflake’s zero-copy cloning is a powerful feature for ML workflows. It allows you to instantly create a snapshot of a database, schema, or table for a tenant—without duplicating storage. This is ideal for:
- Creating isolated dev/staging environments for a tenant
- Running experiments or model training on a consistent data snapshot
- Debugging production issues with a point-in-time copy
Full vs. Partial Tenant Copies (Time-Bounded, Feature-Bounded)
Not all ML use cases require a full copy of tenant data. There are two main ways to reduce data sizes:
- Time-bounded copies: Only clone recent data (e.g., last 30 days) to reduce storage and speed up experimentation.
- Feature-bounded copies: Copy only the columns/features needed for a specific ML task, masking or omitting sensitive fields.
Cloning of the input data vs. storing the output of the feature pipeline
When ML development does not include feature development, it might be sufficient to store the columns/features generated by the data pipeline that is used as the input for the ML model. A robust metadata management and/or feature store will help to track data lineage. It is necessary to also put controls in place for derived data to never leave a tenant context.
Cost Visibility and Cleanup Automation
Frequent cloning and data copying can quickly lead to unexpected storage costs. Best practices:
- Tag all clones and copies with metadata (tenant, environment, purpose, expiration)
- Automate cleanup of temporary datasets after experiments or model validation
- Monitor storage usage and set alerts for orphaned or stale clones
ML Experimentation and Data Cloning
Experimentation is at the heart of ML development. An operational pattern for multi-tenant ML systems is maintaining point-in-time (PIT) snapshots of production tenant data in staging environments for continuous model validation. This approach decouples model development from KPI evaluation, ensuring that performance metrics reflect true model improvements rather than data drift or quality issues.
The Challenge: Data Drift vs. Model Drift
When validating ML models, you need to distinguish whether performance changes are due to:
- Model improvements/regressions: Changes in model code or training
- Data drift: Evolving customer behavior or data quality issues
- Infrastructure changes: Schema updates, feature pipeline bugs
Without stable reference datasets, KPI monitoring becomes unreliable and debugging is difficult. The Solution is regular PIT Snapshots with Fixed Validation Sets.
Use Snowflake's zero-copy cloning to create dated snapshots of production tenant data in staging and keep them as Immutable Validation Sets: Each snapshot remains frozen. New models are evaluated against the same historical data, making results comparable over time.
Automated KPI Computation: Run standardized validation queries against each snapshot to compute metrics (accuracy, precision, RMSE, etc.) for every model version.
Snapshot Rotation: Keep the last N snapshots (e.g., 4-8 weeks) to track model performance trends, then archive or drop older snapshots to control costs.
This pattern also helps detect and isolate data quality problems:
If a model's KPIs drop on a new snapshot but remain stable on older ones, suspect data drift or pipeline bugs—not model regression.
If KPIs degrade across all snapshots, the model itself likely has issues.
Cost and Storage Management
Snapshots consume storage incrementally (only changed data), but can accumulate.
Best practices is to set retention policies (e.g., keep 8 weeks, archive to
cheaper storage after 90 days) and use Snowflake's UNDROP and Time Travel as
fallbacks instead of keeping every daily snapshot.
Deployment Pipelines: From Dev to Prod
Robust deployment pipelines are essential for safely and efficiently moving ML models, features, and data transformations from development to production in multi-tenant Snowflake environments. These pipelines must account for both code and data, and support rapid iteration while minimizing risk.
CI/CD Concepts for Data and Models
The core ML deployment pattern is to treat data pipelines, feature engineering code, and model artifacts as first-class citizens in CI/CD workflows:
- Use version control for all code, configuration, and schema definitions.
- Automate testing of data pipelines and model training in dev/staging before production promotion.
- Integrate model validation and data quality checks as pipeline steps, not afterthoughts.
- Use tools like MLFlow to track metadata, KPIs metrics and artefacts generated during model evaluation. This can include reports, learned model weights and metadata for data snaphots.
Promoting Schemas, Features, and Models Across Environments
Promotion should be automated and auditable:
- Use migration tools or versioned DDL to apply schema changes consistently across dev, staging, and prod.
- Promote feature definitions and model artifacts only after passing validation on production-like data in staging.
- Tag and track all promoted objects with environment, version, and deployment metadata.
Environment-Specific Snowflake Objects
Each environment may require different Snowflake resources:
- Warehouses: Size and configure compute resources to match environment needs (e.g., smaller in dev, larger in prod).
- Roles and RBAC: Restrict access in lower environments, and enforce least-privilege in production.
- Tasks and Streams: Automate data ingestion, transformation, and model scoring with environment-specific schedules and parameters.
Rollback Strategies for Multi-Tenant Deployments
Failures are inevitable—robust rollback is critical:
- Use zero-copy clones and Time Travel to quickly revert schemas or data to a known good state.
- For model rollouts, support canary or phased deployments (e.g., enable new model for a subset of tenants, monitor KPIs, then expand rollout).
- Maintain previous model versions and feature definitions for rapid rollback if regressions are detected.
By treating data, features, and models as deployable artifacts, and automating their promotion and rollback, teams can achieve both agility and safety in multi-tenant ML operations on Snowflake.
Operational Trade-Offs and Lessons Learned
Where Teams Over-Engineer
- Overly granular isolation (e.g., every tenant in its own account/environment) creates a maintenance burden that rarely pays off except for the largest or most regulated customers.
- Excessive manual controls and approval steps slow down experimentation and deployment, leading to bottlenecks and frustrated teams. Data Scientists need access to the data, rather then locking away the production data make sure experiments are run in a controlled/automated fashion.
Where Teams Underestimate Risk
- Under-investing in RBAC, audit logging, and automated data cleanup can lead to costly data leaks or compliance violations.
- Failing to automate environment and tenant provisioning results in configuration drift and inconsistent access boundaries.
- Ignoring cost monitoring for clones, snapshots, and unused resources can cause runaway storage bills.
What to Automate Early
- Environment and tenant provisioning (infrastructure-as-code, templates)
- Data copy/clone tagging, expiration, and cleanup. Expose the capabilities throuhg APIs or CI/CD pipelines
- Schema migrations and model promotion pipelines
- RBAC policy enforcement and regular audits
- Cost monitoring and alerting for storage and compute
The most successful teams revisit their architecture and automation regularly, adapting as scale and requirements evolve. Start simple, automate aggressively, and be ready to tighten controls as your platform and customer base grow.
Closing Thoughts
Tenant isolation in Snowflake for ML is not a one-time architectural decision, but an ongoing operational discipline. As ML platforms scale, the interplay between data, code, and tenant boundaries becomes more complex—and more critical to get right.
Key Takeaways:
- There is no single “best” isolation model; the right approach evolves with your product, customer base, and regulatory landscape.
- Automation, tagging, and regular audits are essential to keep environments, data copies, and access controls manageable at scale.
- ML workloads amplify the risks and operational challenges of multi-tenancy, making reproducibility, rollback, and monitoring non-negotiable.
Looking Forward:
- Expect the boundaries between data engineering, ML, and platform operations to blur further as teams adopt more advanced automation and governance.
- New Snowflake features (e.g., object tagging, masking policies, data clean rooms) will continue to expand the toolkit for safe, scalable multi-tenant ML.
- The most resilient teams treat tenant isolation as a living process—reviewing, testing, and evolving their patterns as both technology and business needs change.
Tenant isolation is a journey, not a destination. By combining strong technical controls with a culture of continuous improvement, teams can deliver both agility and safety for ML-driven products on Snowflake.