#PYDATA
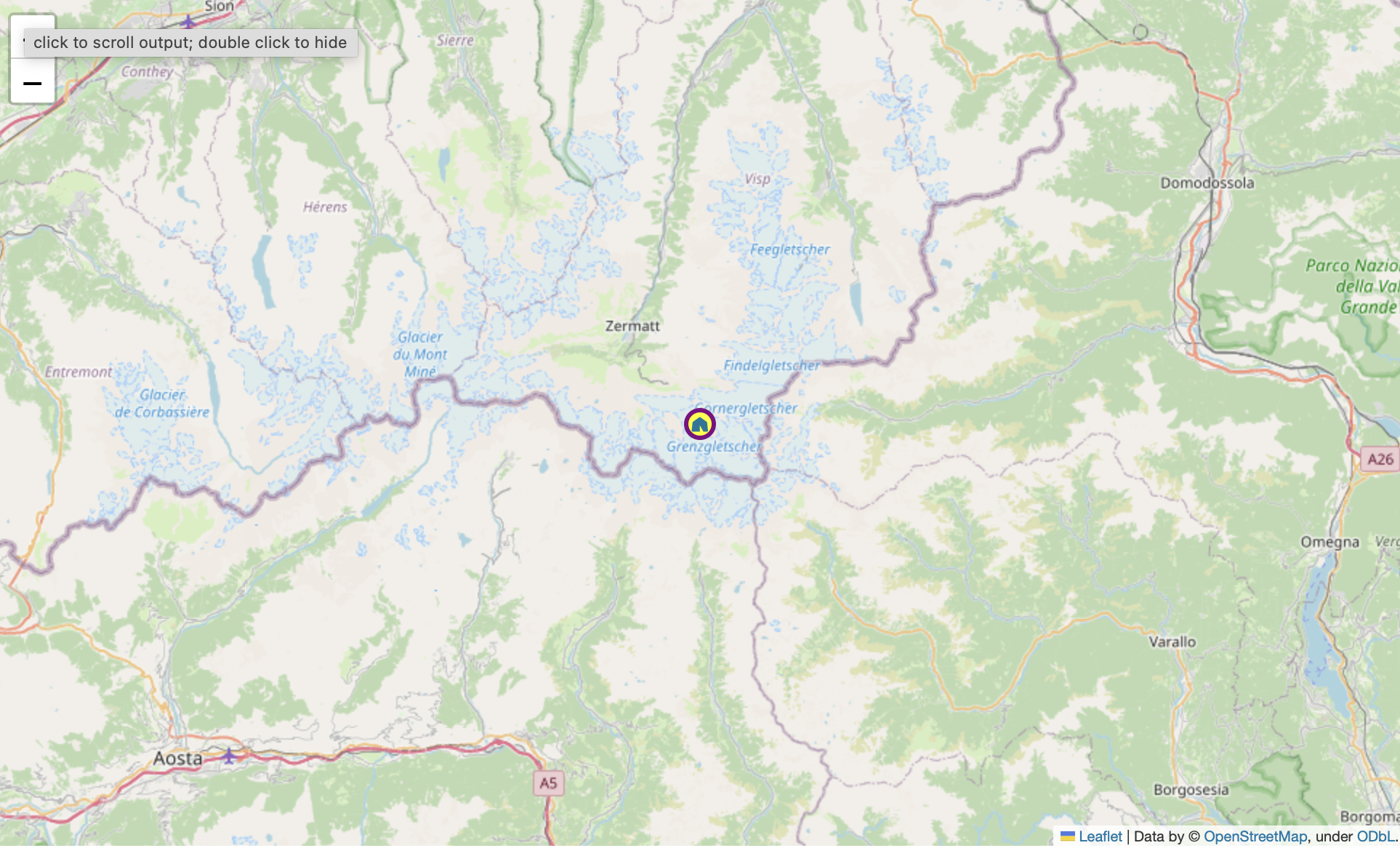

Forecasts crave a rating that reflects the forecast's quality in the context of what is possible in theory and what is reasonable to expect in practice. Read More
Snowflake offers different ways to access and call python from within their compute infrastructure. This post will show how to access python in user defined functions, via stored procedures and in snowpark. Read More

Using SQLAlchemy to create openrowset common table expressions for Azure Synapse SQL-on-Demand Read More

Inspired by Uwe Korns post on DuckDB this post shows how to use Azure Synapse SQL-on-Demand to query parquet files with T-SQL on a serverless cloud infrastructure. Read More
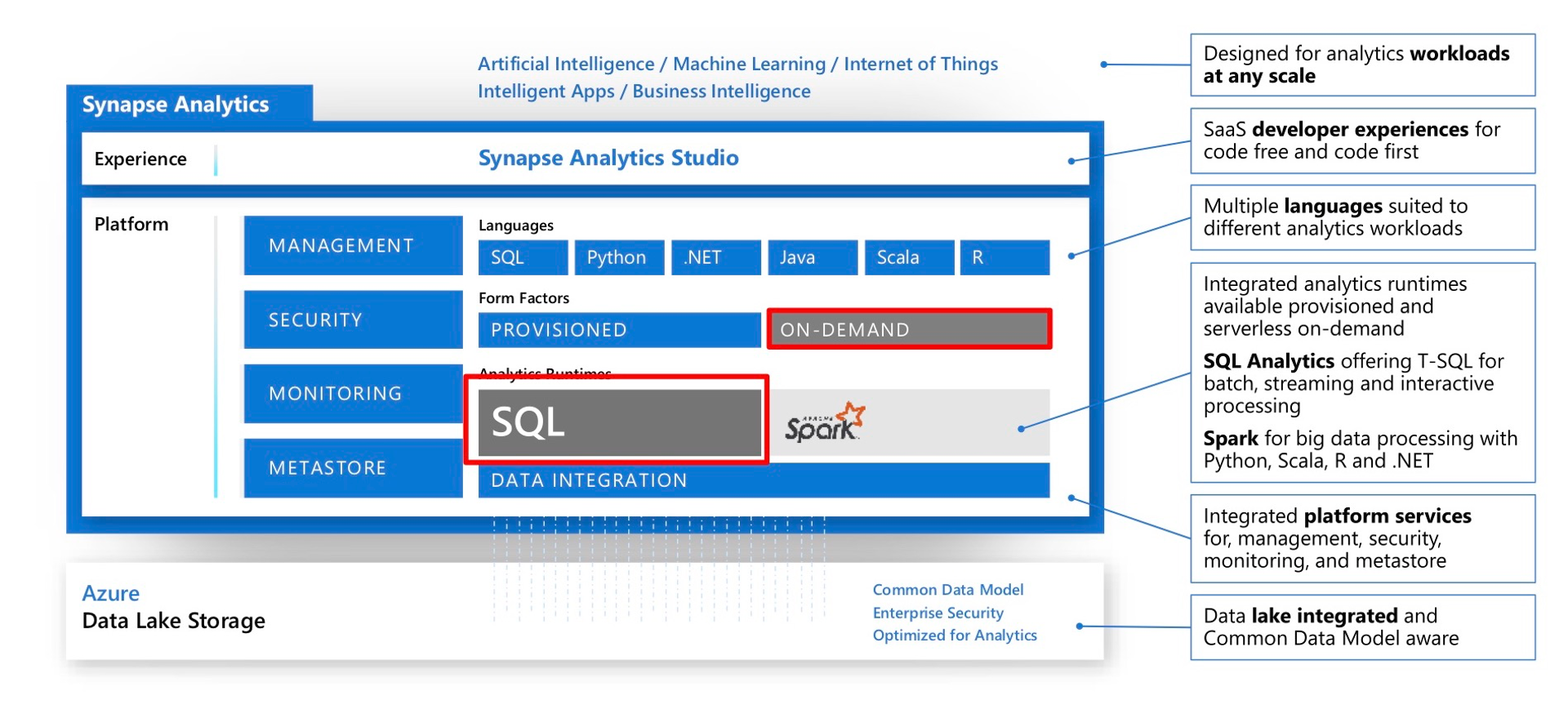
Azure Synapse SQL-on-Demand offers a web client, the desktop version Azure Data studio and odbc access with turbodbc to query parquet files in the Azure Data Lake. Read More

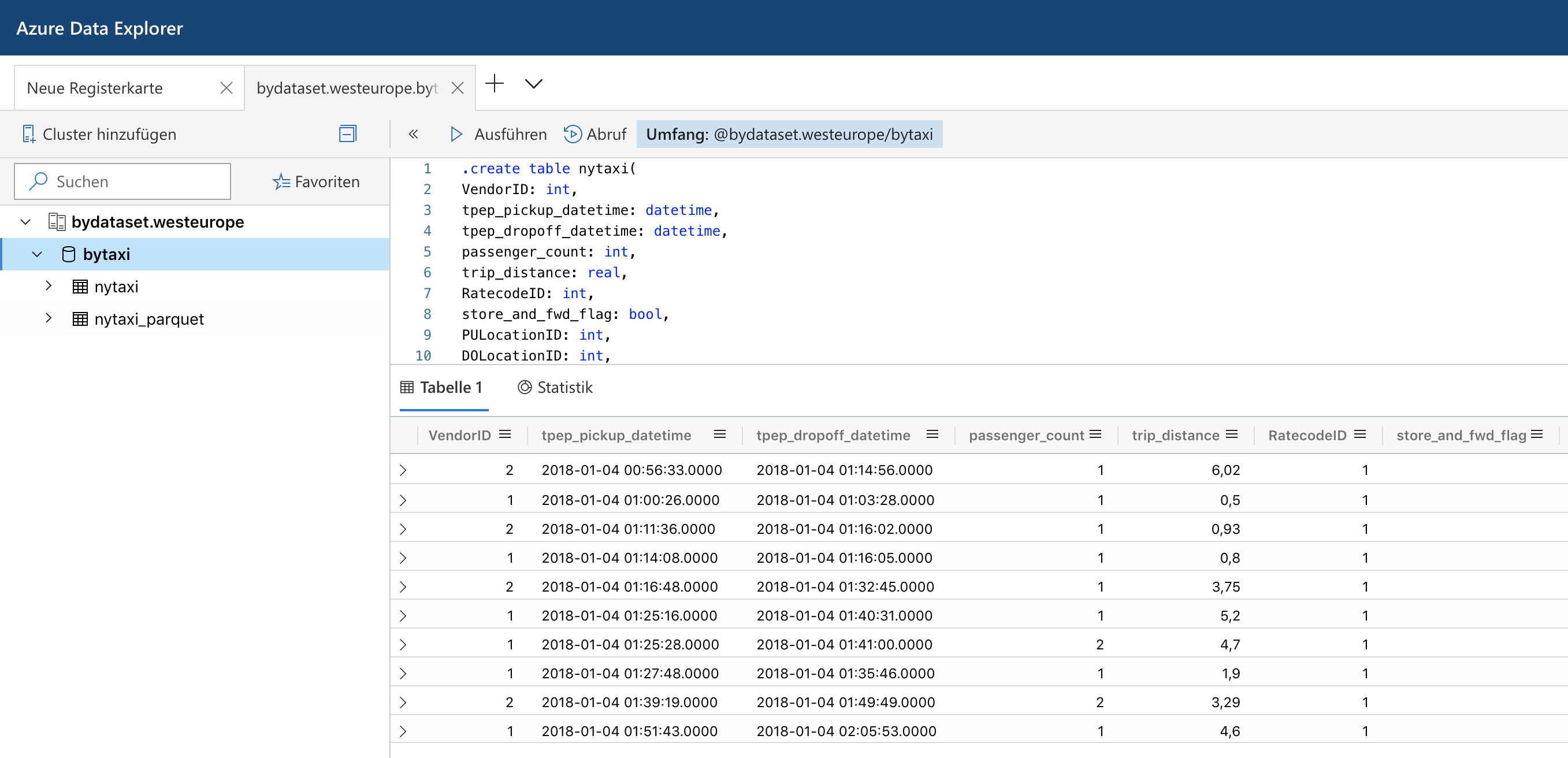
Last summer Microsoft has rebranded the Azure Kusto Query engine as Azure Data Explorer. While it does not support fully elastic scaling, it at least allows to scale up and out a cluster via an API or the Azure portal to adapt to different workloads. It also offers parquet support out of the box which made me spend some time to look into it. Read More
Apache Parquet is a columnar file format to work with gigabytes of data. Reading and writing parquet files is efficiently exposed to python with pyarrow. Additional statistics allow clients to use predicate pushdown to only read subsets of data to reduce I/O. Organizing data by column allows for better compression, as data is more homogeneous. Better compression also reduces the bandwidth required to read the input. Read More

Microsoft has released a beta version of the python client azure-storage-file-datalake for the Azure Data Lake Storage Gen 2 service with support for hierarchical namespaces. Read More

Exasol on Microsoft Azure – automatic deployment in less than 30 minutes Read More

Cloudera Kudu is a distributed storage engine for fast data analytics. The python api is in alpha stage but already usable. Read More
Apache Spark is a computational engine for large-scale data processing. PySpark exposes the Spark programming model to Python. It defines an API for Resilient Distributed Datasets (RDDs) and the DataFrame API. Read More
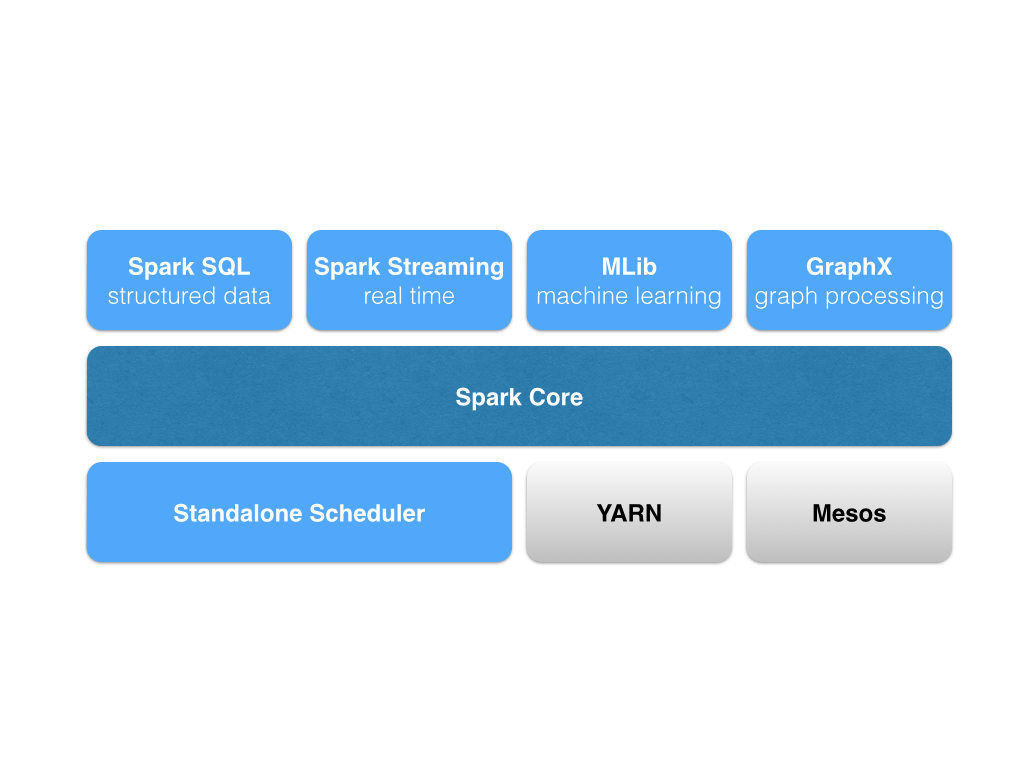
This Talk from PyData 2015 Berlin gives an overview of the PySpark Data Frame API. Read More
